Azure Data Catalog
Azure Data Catalog - Interactive clusters require specific permissions to access this data and without permissions it's not possible to view it. I am looking to copy data from source rdbms system into databricks unity catalog. In the documentation, columndescription is not under columns and that confuses me. You can use the databricks notebook activity in azure data factory to run a databricks notebook against the databricks jobs cluster. Moreover i have tried to put it under annotations and it didn't work. I want to add column description to my azure data catalog assets. I got 100 tables that i want to copy I am using "azure databricks delta lake" I am trying to run a data engineering job on a job cluster via a pipeline in azure data factory. For updated data catalog features, please use the new azure purview service, which offers unified data governance for your entire data estate. I am trying to run a data engineering job on a job cluster via a pipeline in azure data factory. The data catalog contains only delegate permission. You can think purview as the next generation of azure data catalog, and with a new name. I am running into the following error: The notebook can contain the code to extract data from the databricks catalog and write it to a file or database. With this functionality, multiple users (different tenants) should be able to search their specific data (data lake folder) using any metadata tool. But, i tried using application permission. It simply runs some code in a notebook. So, it throws unauthorized after i changed it into user login based (delegated permission). I want to add column description to my azure data catalog assets. Moreover i have tried to put it under annotations and it didn't work. You can use the databricks notebook activity in azure data factory to run a databricks notebook against the databricks jobs cluster. I am trying to run a data engineering job on a job cluster via a pipeline in azure data factory. This notebook reads from databricks unity. The notebook can contain the code to extract data from the databricks catalog and write it to a file or database. For updated data catalog features, please use the new azure purview service, which offers unified data governance for your entire data estate. In the documentation, columndescription is not under columns and that confuses me. It simply runs some code. There will be no adc v2, purview is what microsoft earlier talked with name adc v2. So, it throws unauthorized after i changed it into user login based (delegated permission). I am trying to run a data engineering job on a job cluster via a pipeline in azure data factory. You can use the databricks notebook activity in azure data. The notebook can contain the code to extract data from the databricks catalog and write it to a file or database. Microsoft aims to profile it a bit differently and this way the new name is logical for many reasons: I want to add column description to my azure data catalog assets. Moreover i have tried to put it under. But, i tried using application permission. I'm building out an adf pipeline that calls a databricks notebook at one point. I am looking for a data catalog tool like azure data catalog which will support multitenancy in azure data lake gen2 environment as a data source. It simply runs some code in a notebook. I am using "azure databricks delta. With this functionality, multiple users (different tenants) should be able to search their specific data (data lake folder) using any metadata tool. So, it throws unauthorized after i changed it into user login based (delegated permission). Moreover i have tried to put it under annotations and it didn't work. Interactive clusters require specific permissions to access this data and without. For updated data catalog features, please use the new azure purview service, which offers unified data governance for your entire data estate. I am running into the following error: So, it throws unauthorized after i changed it into user login based (delegated permission). I am trying to run a data engineering job on a job cluster via a pipeline in. For updated data catalog features, please use the new azure purview service, which offers unified data governance for your entire data estate. I am using "azure databricks delta lake" In the documentation, columndescription is not under columns and that confuses me. I am trying to run a data engineering job on a job cluster via a pipeline in azure data. This notebook reads from databricks unity catalog tables to generate some data and writes to to another unity catalog table. Microsoft aims to profile it a bit differently and this way the new name is logical for many reasons: Interactive clusters require specific permissions to access this data and without permissions it's not possible to view it. I got 100. But, i tried using application permission. I am running into the following error: In the documentation, columndescription is not under columns and that confuses me. You can think purview as the next generation of azure data catalog, and with a new name. There will be no adc v2, purview is what microsoft earlier talked with name adc v2. You can think purview as the next generation of azure data catalog, and with a new name. The notebook can contain the code to extract data from the databricks catalog and write it to a file or database. Moreover i have tried to put it under annotations and it didn't work. With this functionality, multiple users (different tenants) should be able to search their specific data (data lake folder) using any metadata tool. I want to add column description to my azure data catalog assets. I got 100 tables that i want to copy This notebook reads from databricks unity catalog tables to generate some data and writes to to another unity catalog table. I'm building out an adf pipeline that calls a databricks notebook at one point. I am trying to run a data engineering job on a job cluster via a pipeline in azure data factory. I am looking to copy data from source rdbms system into databricks unity catalog. You can use the databricks notebook activity in azure data factory to run a databricks notebook against the databricks jobs cluster. The data catalog contains only delegate permission. Microsoft aims to profile it a bit differently and this way the new name is logical for many reasons: But, i tried using application permission. I am using "azure databricks delta lake" For updated data catalog features, please use the new azure purview service, which offers unified data governance for your entire data estate.
Azure Data Catalog V2 element61
Integrate Data Lake Storage Gen1 with Azure Data Catalog Microsoft Learn
Microsoft Azure Data Catalog Glossary Setup 4 Sql Mel vrogue.co
Getting started with Azure Data Catalog

Quickstart Create an Azure Data Catalog Microsoft Learn
Azure Data Catalog DBMS Tools

Azure Data Catalog YouTube
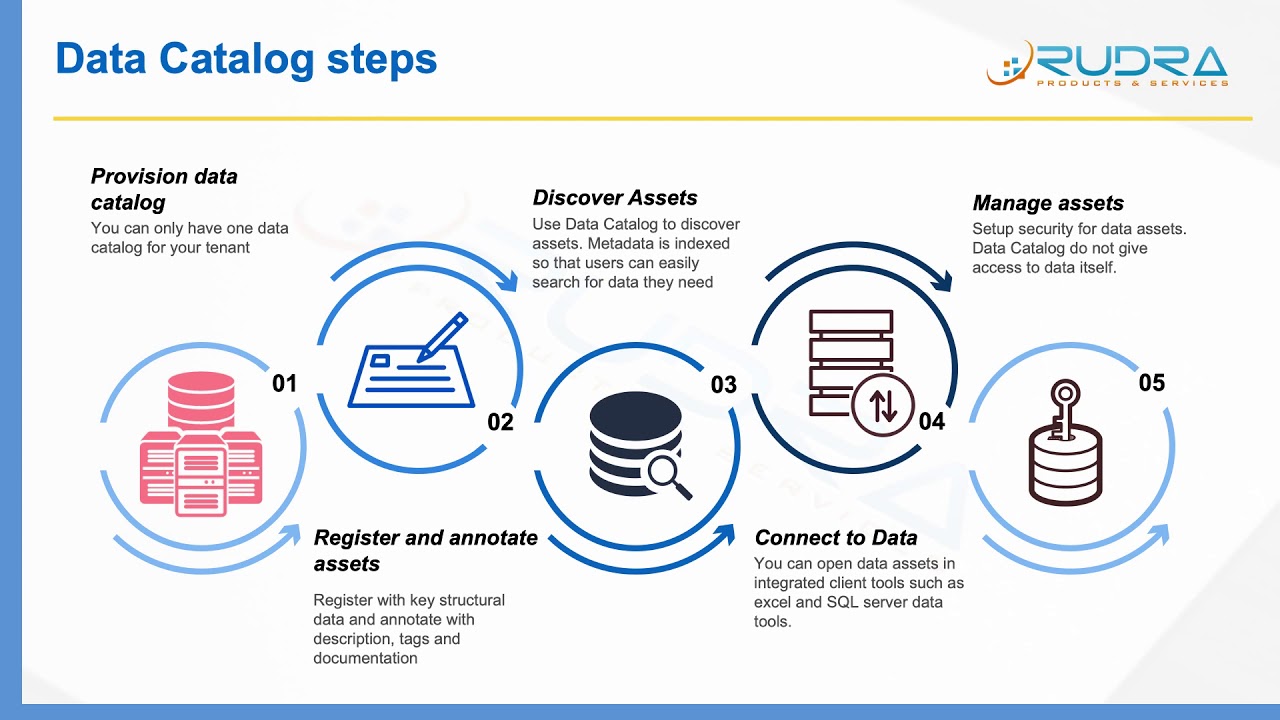
Introduction to Azure data catalog YouTube
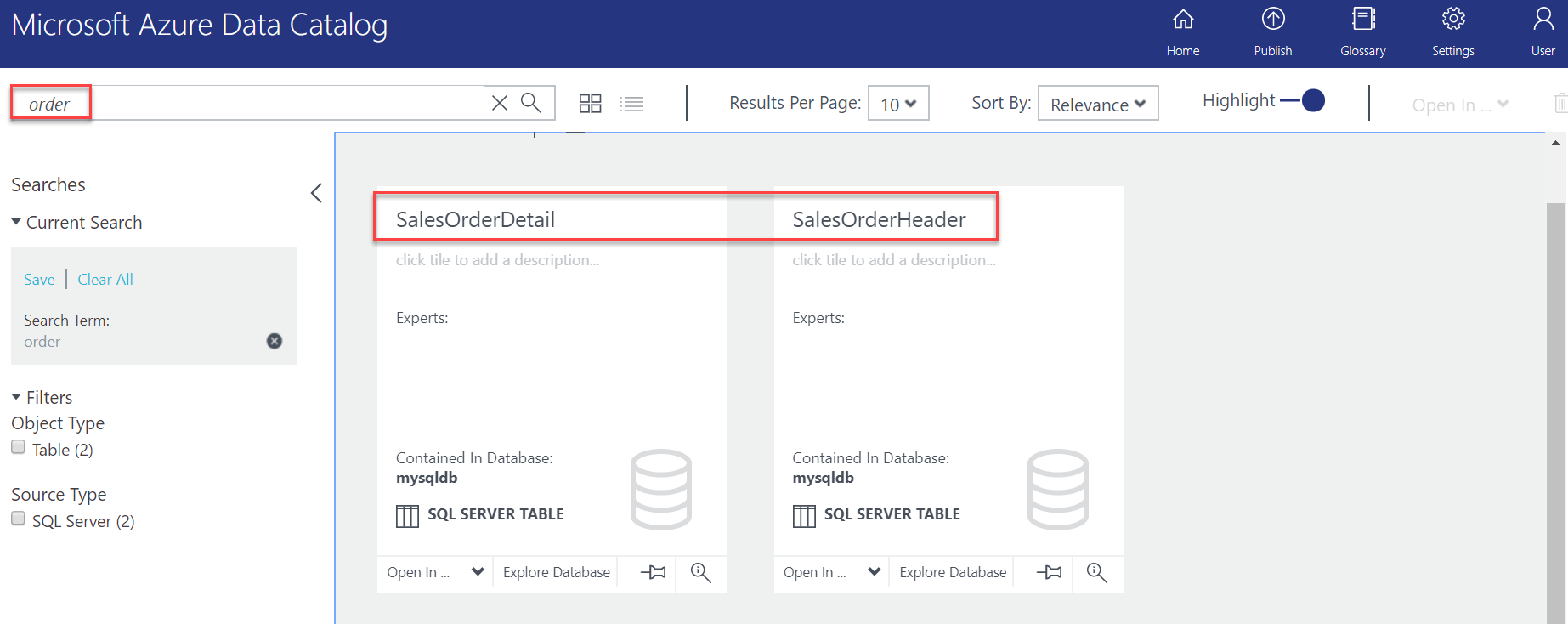
Getting started with Azure Data Catalog
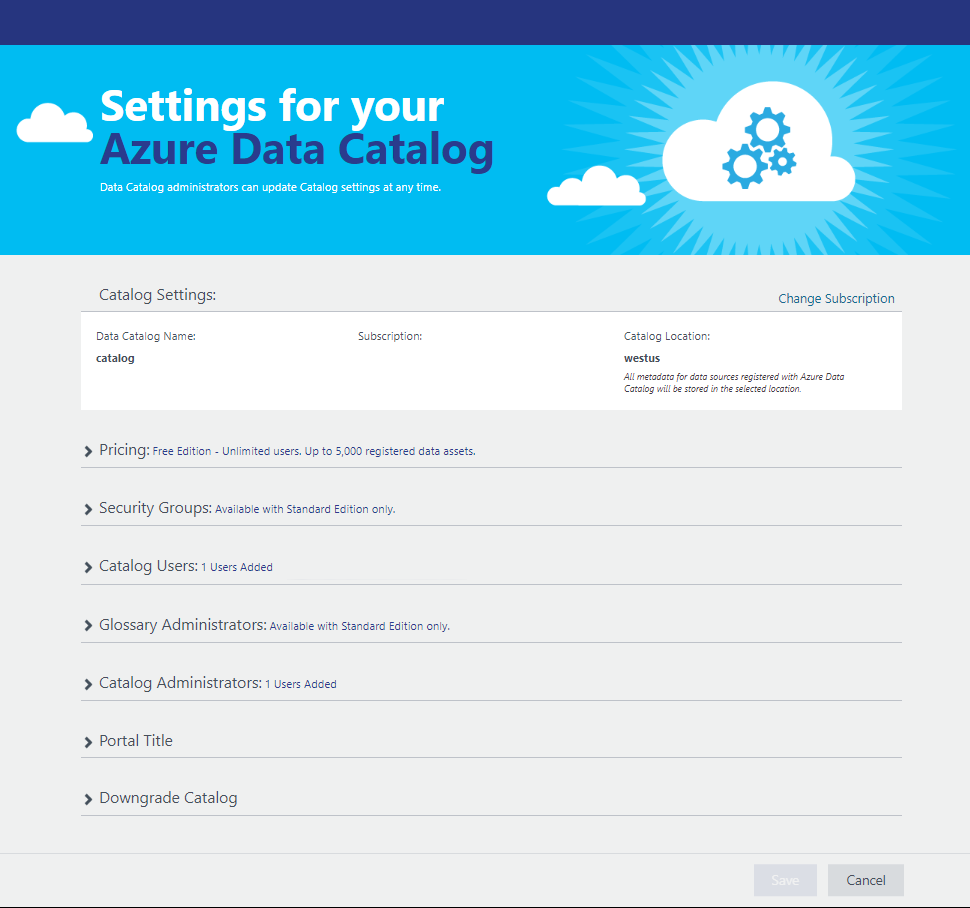
Quickstart Create an Azure Data Catalog Microsoft Learn
It Simply Runs Some Code In A Notebook.
There Will Be No Adc V2, Purview Is What Microsoft Earlier Talked With Name Adc V2.
Interactive Clusters Require Specific Permissions To Access This Data And Without Permissions It's Not Possible To View It.
So, It Throws Unauthorized After I Changed It Into User Login Based (Delegated Permission).
Related Post: